業務ソリューション事業本部 イノベーション推進部
COLUMN
コラム
BPO
AI-OCR
AI-OCRの精度は100%ではない!

田口 裕太
2021.07.30
エントリー業務を含め、長年OCR技術に触れている私から、AI-OCRの精度を100%に近づける方法を複数回に分けて公開したいと思います。
マス目に一文字ずつ記入する昔ながらのOCRと異なり、近年はフリーピッチといって枠内に自由に記入された文字の読み取りが可能な「AI-OCR」が普及しています。
AI-OCR製品は大きく定型帳票と準定型帳票に対応したものがあります。後者は決まった雛形でなくても、それなりに場所を見つけて必要な箇所をOCRしてくれるもので、かなり精度の高い製品も増えてきました。
私の部署では両方の製品を検証していますが、日々技術は進化しつつも、残念ながら現時点では100%の正確性を実現する製品は無いようです。
その理由として4点あげます。
理由その1:画像イメージの質の問題
スキャナーや複合機で紙をイメージ化する際、紙の厚さ、印字の色、濃度、ほこりの付着などで精度は大きく左右されます。
例:ほこりがついている

理由その2:文字そのものの問題
手書き文字のハードルは依然として高く、くせ字や枠から大きくはみ出した字、ミスを二重線で消しているケースの対応は非常に困難です。
昨今のAI-OCR製品にはこれらに精度高く対応するものも増えていますが、やはり100%対応できているとは言いきれないのが実情です。
例:枠からはみ出している
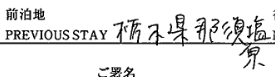
理由その3:活字であっても難しいケース
ビジネスシーンでも多く利用するWordやPowerPointで使うフォント以外にも、世の中にはオリジナルのフォントがたくさんあります。
手書き文字と同じで、クセのあるフォントの場合読み取れないケースも少なからずあります。
例:クセのあるフォント

理由その4:枠線の問題
全くの白紙に文字だけが書かれているパターンは極めて少なく、表のマス目の中、あるいは横線の上に文字が記入または印字されていることがほとんどです。その場合、枠線に文字が重なってしまい、線なのか文字の一部なのかの判断が難しくなります。
昨今は各社が競って枠線と文字と分離し、文字だけを読み取る技術を確立しています。しかしそこにも精度の問題はつきまといます。
例:枠線と文字が重なっている
深層学習を使ったAI-OCR技術は既に普及し、後進の当社がレッドオーシャンに飛び込み一からAI-OCRのエンジンを作り上げることは断念しました。その代わり、既に世に出ている優れたAI-OCRサービスの結果と、従来のエントリー会社が手打ちした文字を並列に並べ、差異がある場合だけ人的に補正する手法※を確立しました。次回はその詳細をお伝えしたいと思います。
※ 通常、人手にてダブルエントリーするところを、人(シングルエントリー)とOCRを組み合わせることで比較的安価でご提供する手法です
著者プロフィール
田口 裕太
データエントリー会社に勤務後、さくら情報システムに入社しました。
エントリー業務の効率化を目的としたシステム開発経験を元にAI-OCR活用に注力しています。複数社のサービス検証を経て、それぞれの利点を生かしたシステム連携を実現しましたが、さらなる精度向上を求めて日々研究を重ねています。
この記事をシェアする



RECOMMEND
